 |
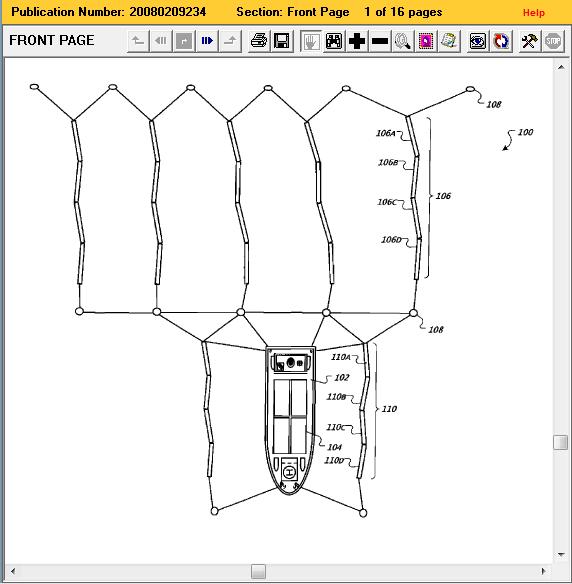
| 1. Diagram from Google's patent application for floating data centers. |
The intention is for the portrayal to be as realistic as possible. Anything I write about either exists today as a product, is in active research, or is extrapolated from current trends. The process I use to extrapolate tech trends is described in an article I wrote called How to Predict the Future. I've also drawn upon my twenty years as a software developer, my work on social media strategy, and a bit of experience in writing and using recommendation engines, including competing for the Netflix Prize.
Let's examine a few specific ideas manifested in the books and see where those ideas originated.
- Floating Data Centers: (Status: Research) Google filed a patent in 2007 for a floating data center based on a barge. The patent application was discovered and shared on Slashdot in 2008. Like many companies, filing a patent application doesn't mean that Google will be deploying ocean-based data centers any time soon, but simply that the idea is feasible, and they'd like to own the right to do so in the future, if it becomes viable. And of course, there is the very real problem of piracy.
- Portland Wave Converter: (Status: Real) In Avogadro Corp I describe the Portland Wave Converter as a machine that converts wave motion into electrical energy. This was also described as part of the Google patent application for a floating data center. (See diagram 1.) But Pelamis Wave Power is an existing commercialization of this technology. You can buy and use wave power converters today. Pelamis did a full-scale test in 2004, installed the first multi-machine farm in 2008 off the coast of Portugal, is doing testing off the coast of Scotland, and is actively working on installing up to 170MW in Scottish waters.
- Underground Data Center: (Status: Real) The Swedish data center described as being in a converted underground bunker is in fact the Pionen data center owned by Bahnhof. Originally a nuclear bunker, it's housed nearly a hundred feet underground and is capable of withstanding a nuclear attack. It has backup power provided by submarine engines and triple redundant backbone connections to the Internet and fifteen full-time employees on site.
- Netflix Prize: (Status: Real) A real competition that took place from 2006 through 2009, the Netflix Prize was a one million dollar contest to develop a better recommendation than Netflix's original Cinematch algorithm. Thousands of people participated, and hundreds of teams beat Netflix's algorithm, but only one team was the first to better it by 10%, the required threshold for payout. I entered the competition and realized within a few weeks that there were many other ways recommendation engine technology could be put to use, including a never-before-done approach to customer support content that increased the helpfulness of support content by 25%.
- Email-to-Web Bridge: (Status: Real) At the time I wrote Avogadro Corp, IBM had a technical paper describing how they build an email-to-web bridge as a research experiment. Five years later, I can't seem to find the article anymore, but I did find some working examples of services that do the same thing. In fact, www4mail appears to have been working since 1998.
- Decision-Making via Email: (Status: Real) From 2003 to 20011, I worked in a position where everyone I interacted with in my corporation was physically and organizationally remote. We interacted daily via email and weekly via phone meetings. Many decisions were communicated by email. They might later be discussed in a meeting, but if a communication came down by a manager, we'd just have to work within the constraints of that decision. Through social engineering, it possible to make those emails even more effective. For example, employee A, a manager, is about to go on vacation. ELOPe sends an from employee A to employee B, explaining a decision that was making, and asking employee B to handle any questions for that decision. Everyone else receives an email saying the decision was made, and ask employee B if there are questions. The combination of an official email announcement plus a very real human contact to act as point person becomes very persuasive. On the other hand, some Googlers have read Avogadro Corp, and they've said the culture at Google is very different. They are centrally located and therefore do much more in face to face meetings.
- iRobot military robots: (Status: Real) iRobot has both military bots and maritime bots, although what I envisioned for the deck robots on the floating data centers is closer to the Foster-Miller Talon, an armed, tank-style robot. The Gavia is probably the closest equivalent to the underwater patrolling robots. It accepts modular payloads, and while it's not clear if that could include an offensive capability, it seems possible.
- Language optimization based on recommendation engines: (Status: Made Up) Unfortunately, not real. It's not impossible, but it's also not a straightforward extrapolation. There's hard problems to solve. Jacob Perkins, CTO of Weotta, wrote an excellent blog post analyzing ELOPe's language optimization skills. He divides the language optimization into three parts: topic analysis, outcome analysis, and language generation. Although challenging, topic analysis is feasible, and there are off-the-shelf programming libraries to assist with this, as there also are for language generation. The really challenging part is the outcome analysis. He writes:
"This sounds like next-generation sentiment analysis. You need to go deeper than simple failure vs. success, positive vs. negative, since you want to know which email chains within a given topic produced the best responses, and what language they have in common. In other words, you need a language model that weights successful outcome language much higher than failure outcome language. The only way I can think of doing this with a decent level of accuracy is massive amounts of human verified training data. Technically do-able, but very expensive in terms of time and effort.
What really pushes the bounds of plausibility is that the language model can't be universal. Everyone has their own likes, dislikes, biases, and preferences. So you need language models that are specific to individuals, or clusters of individuals that respond similarly on the same topic. Since these clusters are topic specific, every individual would belong to many (topic, cluster) pairs. Given N topics and an average of M clusters within each topic, that's N*M language models that need to be created. And one of the major plot points of the book falls out naturally: ELOPe needs access to huge amounts of high end compute resources."
This is a case where it's nice to be a science fiction author. :)
 |
| Pelamis Wave converter in action. |
 |
| Pionen Data Center. (Src: Pingdom) |
| Foster-Miller Armed Robot (Src: Wikipedia) |
I hope you enjoyed this post. If you have any other questions about the technology of Avogadro Corp, just let me know!
No comments:
Post a Comment